EventStorming
Praca przy projekcie legacy zwykle nie jest prosta. Kod systemu potrafi być skomplikowany, przerośnięty, wręcz przesiąknięty siecią wzajemnych powiązań. W początkowych fazach pracy z projektem zwykle mocno utrudnia to jego zrozumienie i wprowadzanie oczekiwanych przez użytkowników zmian. Oczywiście nie zawsze wprowadzenie zmiany w systemie będzie trudne. Zmiana lokalna w postaci na przykład drobnego rozszerzenia warunku czy kroków wyliczającego wartość algorytmu nie wymaga od nas zwykle znajomości całego systemu. W innym przypadku jednak wiedza ta staje się często kluczowa, więc musimy ją w jakiś sposób zgromadzić.
Zwykle informacja, JAK właściwie działa system, jest mocno rozproszona w zespole — każdy coś wie o jego poszczególnych częściach. Specjalizacja w jednym obszarze powoduje często, że z oczu znika nam wpływ, jaki obszar ten wywiera na resztę systemu. Zdarza się, że wiedza, jak właściwie działa konkretny fragment systemu, jest skupiona w zaledwie jednej osobie — tak zwanego Dungeon Mastera, i tylko ona ma prawo wprowadzania modyfikacji. W takiej sytuacji zmiany są wprowadzane szybko i na czas, jednak nie w przypadku urlopu.
Wiedzę o działaniu systemu możemy także pozyskać od interesariuszy biznesowych. Może jednak pojawić się tu bardzo istotny problem komunikacyjny. Osoby te mówią przede wszystkim językiem funkcji biznesowych, CO i DLACZEGO się dzieje, dla których nasz język techniczny opisujący, JAK dana funkcja jest implementowana, jest po prostu niezrozumiały. Próba rozmowy z naszej strony o nowych funkcjach, zaczynając od JAK, jest zwykle z góry skazana na porażkę.
Przypadłością niejednego projektu są rozmowy o nowych funkcjach kategoriami tabelek i powiązanych z nimi ekranów. Gdy wszystkie strony przyzwyczaiły się do takiej komunikacji, całkowicie zdominowanej przez JAK, dotarcie do prawdziwych potrzeb biznesowych i DLACZEGO dana funkcja jest potrzebna, wymaga bardzo dużego wysiłku. Nie zapominajmy przy tym, że zwykle istnieje wiele sposobów realizacji JAK, dla jednego tylko CO (patrz: "CO?", a "JAK?").
Podsumowując powyższe, możemy wyróżnić następujące problemy w projekcie legacy:
- trudny do zrozumienia kod źródłowy
- wysokie sprzężenie elementów systemu
- rozproszenie wiedzy o sposobie działania systemu
- skupienie kluczowej wiedzy wśród wąskiej grupy osób
- różne sposoby komunikacji zaangażowanych w projekt osób
- pomijanie w komunikacji informacji o realnych potrzebach biznesowych
Istnieje sporo technik ich rozwiązania. Możemy skorzystać z różnego rodzajów diagramów, form warsztatów i dyskusji. Jedną z najefektywniejszych opcji jest tu EventStorming — z racji niskiego progu wejścia, jak i możliwość bezpośredniego zastosowania wyniku warsztatu w projekcie.
Zdarzenia
Główna idea EventStormingu opiera się na przedstawieniu danego problemu np. przebiegu skomplikowanego procesu biznesowego, jako serii występujących po sobie zdarzeń. Zdarzenie jest tu podstawowym źródłem informacji. Językiem domenowym opisuje istotną zmianę zachodzącą w systemie. Może ono powodować wystąpienie w nim kolejnych zdarzeń, a jego umiejscowienie na osi czasu sprawia, że nawet bardzo skomplikowane procesy stają się proste do zrozumienia — niezależnie od roli osoby w projekcie.
EventStorming w pigułce:
- mapowanie procesu biznesowego jako sekwencji zdarzeń
- zdarzenie opisuje istotną, zachodzącą w procesie zmianę
- zdarzenie opisane jest językiem biznesowym
- uczestnicy sesji wykorzystują język domenowy do rozmowy, niezależnie od pełnionej w projekcie roli
Poziomy EventStormingu
W nowych projektach najczęściej stosowany pełny format warsztatu zakłada przejście przez trzy poziomy, na których nasze rozumienie problemu jest stopniowo pogłębiane. Od początkowego pomysłu, aż do uzyskania propozycji rozwiązania.
Tymi poziomami są:
- Big Picture EventStorming
- Process Level EventStorming
- Design Level EventStorming
Big Picture EventStorming
Zwykle rozpoczynamy pracę od Big Picture, czyli wysokopoziomowego spojrzenia na problem. Pozwala on na bardzo dobre rozpoznanie tematu i wybranie miejsc do dalszej eksploracji dzięki:
- ułożeniu zdarzeń na osi czasu,
- wzbogaceniu ich o powiązanych aktorów,
- zaangażowaniu w proces systemów zewnętrznych,
- przepływom wartości materialnych i niematerialnych,
- pomysłom na możliwe usprawnienia,
- zidentyfikowaniu potencjalnych ryzyk czy problemów.
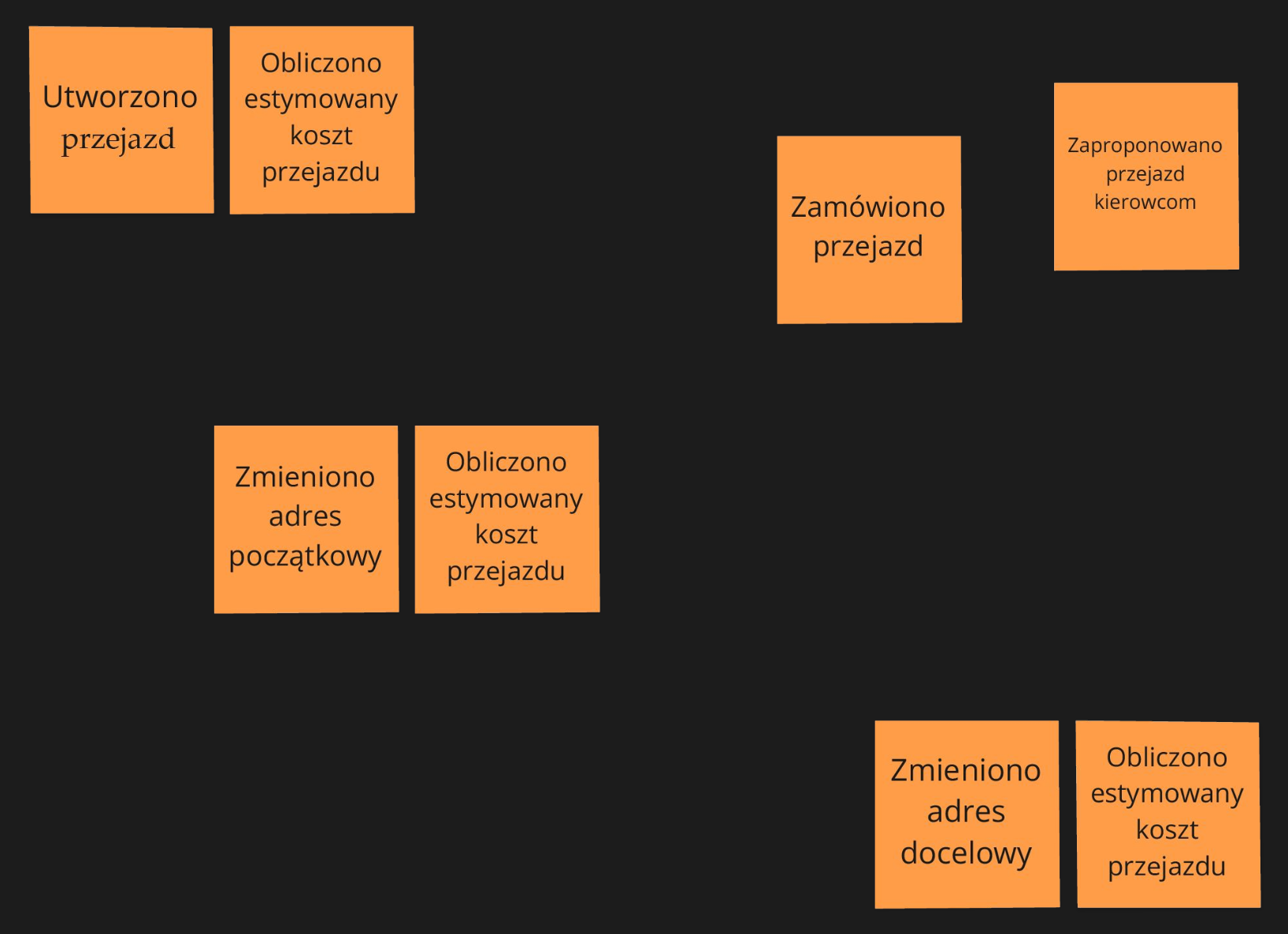
Process Level EventStorming
Eksplorację kontynuujemy, korzystając z tzw. Process Level EventStormingu, w którym zestaw elementów konstrukcyjnych rozszerza się o:
- koncept kierowanego do procesu rozkazu (komendy, a więc żądania o zmianę),
- danych potrzebnych aktorowi do podejmowania takich decyzji
- polityki, dzięki której możemy opisywać bardziej złożone i długotrwałe procesy.
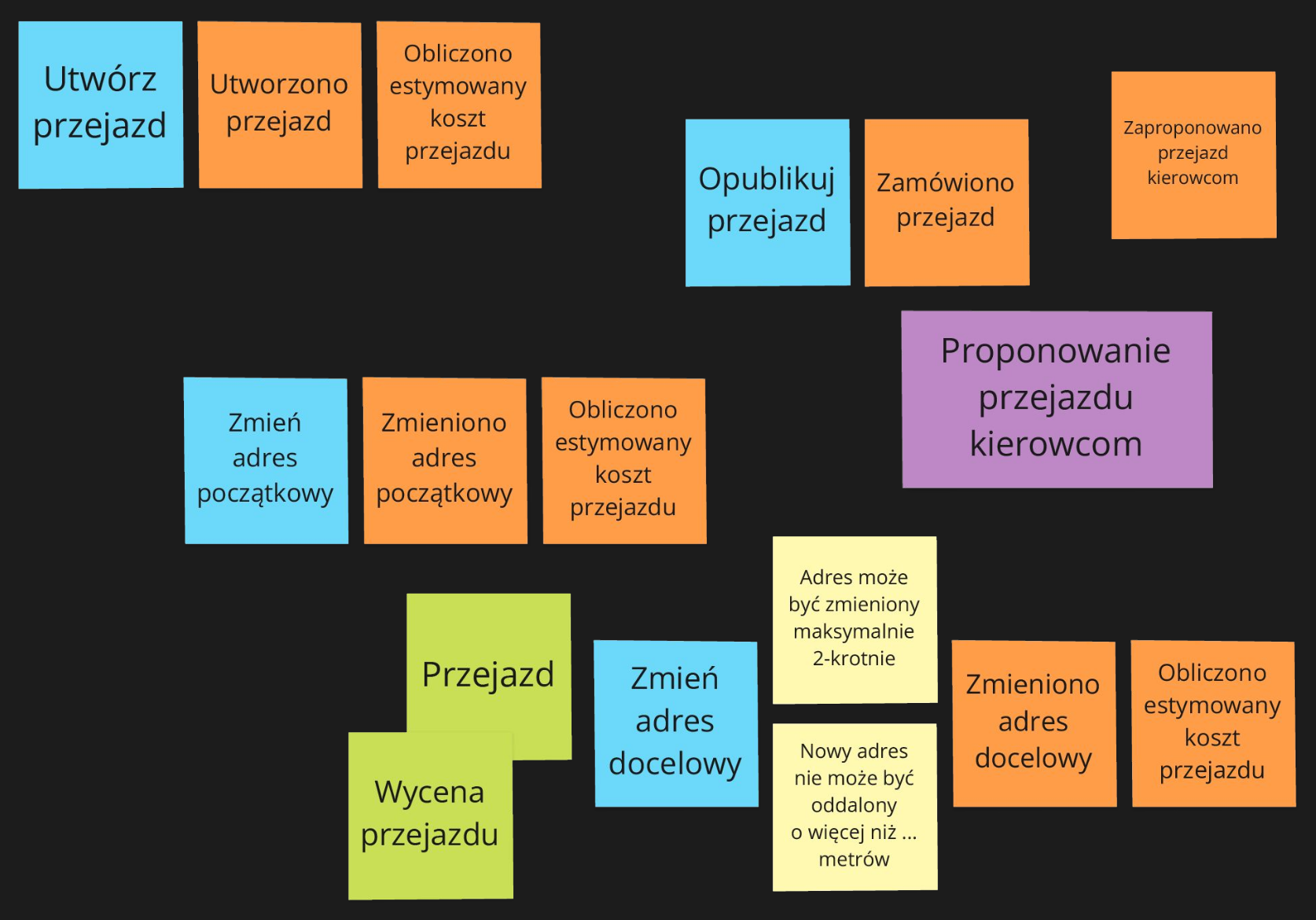
Design Level EventStorming
Ostatnim poziomem jest Design Level EventStorming, czasem także nazywany Software Design EventStormingiem. Mając wiedzę o potrzebnych w systemie funkcjach, możemy zaproponować strukturę rozwiązania technicznego np. występujących w systemie obiektów i ich odpowiedzialności. To jest już coś, co bezpośrednio przekłada się na prace implementacyjne w projekcie.

Praktyczna możliwość zastosowania i rodzaje zdarzeń
Można by jeszcze sporo powiedzieć o technice EventStormingu, idei jej trzech poziomów, jak i mapowaniu na kolejne fazy Divergent, Emergent, Convergent procesu stormingowego. Chcemy jednak pokazać nasze doświadczenia i praktyczny sposób, w jaki stosujemy EventStorming w projektach legacy. Nawet takich, których historia jest ponad 30-letnia. Skupiamy się przy tym zarówno na rozpoznaniu projektu, jak i proponowaniu konkretnych rozwiązań, projektowania odpowiednich granic obiektów i modułów. Przedstawiamy także miejsca, gdzie odchodzimy od książkowej struktury warsztatu i powody, dla których to robimy.
Przykładowo, nie każde zdarzenie, jakie pojawia się podczas sesji Big Picture, może być dla nas równie interesujące. Przyjrzyj się następującym przykładom z produktu Cabs:

Istnieją jednak między nimi zasadnicze różnice. Każde z nich prawdopodobnie jest dla kogoś interesujące. To zwykle właśnie powód ich pojawienia się w trakcie warsztatu, jednak są one związane kolejno:
- ze środowiskiem otaczającym nasz system, który raczej nie jest obecnie zainteresowany faktem, że kierowca uruchomił właśnie pojazd,
- z interfejsem użytkownika, w którym przedstawiane są poszczególne informacje, a który ma zwykle tendencję do szybkiej ewolucji i zmian, nie wpływając przy tym na strukturę rozwiązania backendowego,
- z różnego rodzaju sprawdzeniami i weryfikacjami, które, tak jak poprzednie przykłady, także nie modyfikują stanu naszego systemu,
- z prawdziwą zmianą biznesową, która pociąga za sobą kolejne akcje w systemie, które są bardzo istotne z punktu widzenia przedsiębiorstwa,
- z działaniem technicznym, związanym z realizacją funkcji biznesowej, dodatkowo potencjalnie trudnym do zrozumienia osobom niezwiązanym z programowaniem.
Stając przed wyzwaniem poznania zasady działania systemu, w pierwszej kolejności, warto rozpocząć od zmian biznesowych, a dopiero w dalszych etapach, jeśli to potrzebne, poznać te pozostałe. Zauważ przy tym, że wskazane zdarzenia domenowe mają opisywać istotne zmiany w procesie biznesowym. Nie mówimy tu nic o sposobie, w jaki zostały one zaimplementowane w systemie. Zdarzenie "Zakończono przejazd" mogło zostać technicznie zrealizowane w postaci zmiany właściwości obiektu po wywołaniu na nim metody, wywołania procedury składowanej w bazie danych lub też utworzenie, wyemitowanie i zapisanie w Event Storze odpowiedniego zdarzenia. Najważniejsze na tym etapie jest poznanie biznesowego CO. JAK to tylko detal implementacyjny, który być może właśnie chcemy zmienić.
As-Is i To-Be
Wykorzystując EventStorming w projekcie legacy, często chcemy zobaczyć jego dwie wersje:
- pierwszą — uzyskaną możliwie najszybciej, opisującą aktualny zastany stan projektu,
- drugą — przedstawiającą projekt za X miesięcy, czyli nasze rozwiązanie docelowe.
W szkoleniu krok po kroku przedstawiamy wykorzystywany przez nas sposób tworzenia obu wersji oraz możliwości ich wykorzystania w projekcie. Nazywamy je odpowiednio As-Is oraz To-Be:
- As-Is - przedstawienie stanu obecnego projektu, ze wszystkimi jego problemami i wyzwaniami,
- To-Be - przedstawieni stanu oczekiwanego, w pewnej perspektywie czasu.
Najczęściej zależy nam na możliwie jak najszybszym uzyskaniu tego pierwszego obrazu. W tym celu można skorzystać z bardzo uproszczonego Big Picture EventStormingu, podczas którego należy skupić się jedynie na zmapowaniu zachodzącym w systemie zdarzeń zmieniających jego stan. Pamiętając jednak, aby opisać każde z nich językiem biznesowym. "Zmieniających jego stan" jest tu często szczególnie istotne, ponieważ przystępując do refaktoryzacji projektu legacy, zwykle nie jesteśmy zainteresowani jego szerszą biznesową analizą czy też wpływem na systemy zewnętrzne. Obserwowalne zachowania powinny pozostać tu niezmienione.
Istnieje spora szansa, że w trakcie rozmowy uzyskamy wystarczająco dużo informacji, dzięki którym zidentyfikujemy miejsce w kodzie źródłowym, gdzie dana zmiana jest realizowana. Dzięki pomocy IDE idąc w górę wywołań, dojdziemy być może aż do odpowiedniego widoku. Połączymy biznesowe CO i DLACZEGO z technicznym, JAK i GDZIE, mapując poszczególne elementy konstrukcyjne EventStormingu na konkretne fragmenty aplikacji.
W tym kontekście zdarzenia domenowe:
- opisują istotne zmiany w procesie biznesowym
- nie ujawniają sposobu implementacji
- będą występować w zrefaktoryzowanym systemie
- pozwalają na powiązanie języka biznesowego z kodem źródłowym systemu
Given-when-then
Zdarzenia domenowe zidentyfikowane w trakcie warsztatu, są obserwowalnymi zachowaniami. Znając zarówno zlecany przez użytkownika systemu rozkaz, jak i wszystkie oczekiwane obserwowalne zachowania, jesteśmy w zasadzie o krok od sformalizowania oczekiwań biznesowych. Pozostaje tylko określić warunki początkowe, przy jakich poszczególne rozkazy skutkują danymi zdarzeniami, a uzyskaną wiedzę zapisać do późniejszego wykorzystania, w wysokopoziomowych testach naszego systemu, których w legacy zwykle nie ma.
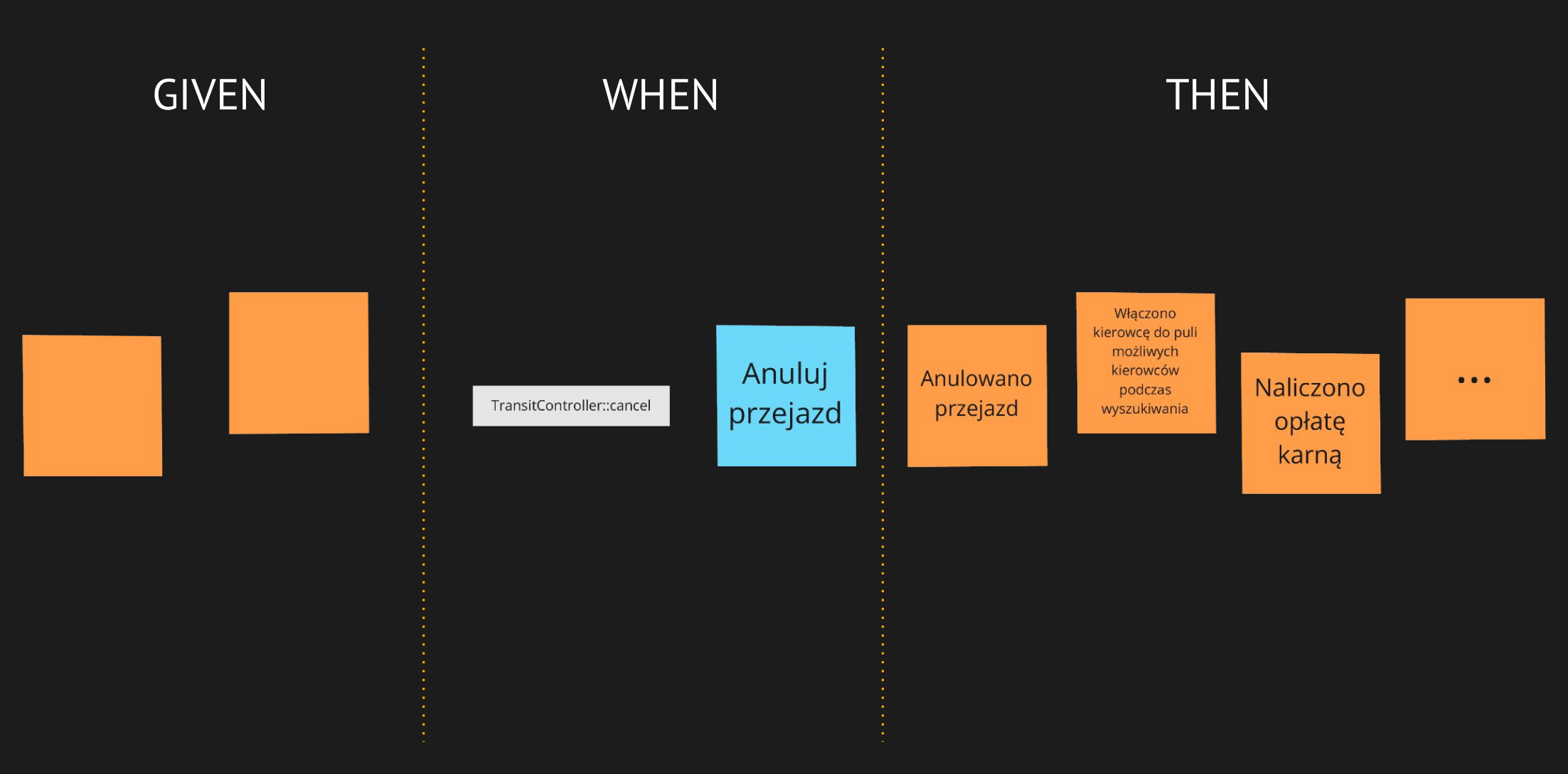
Przykład:
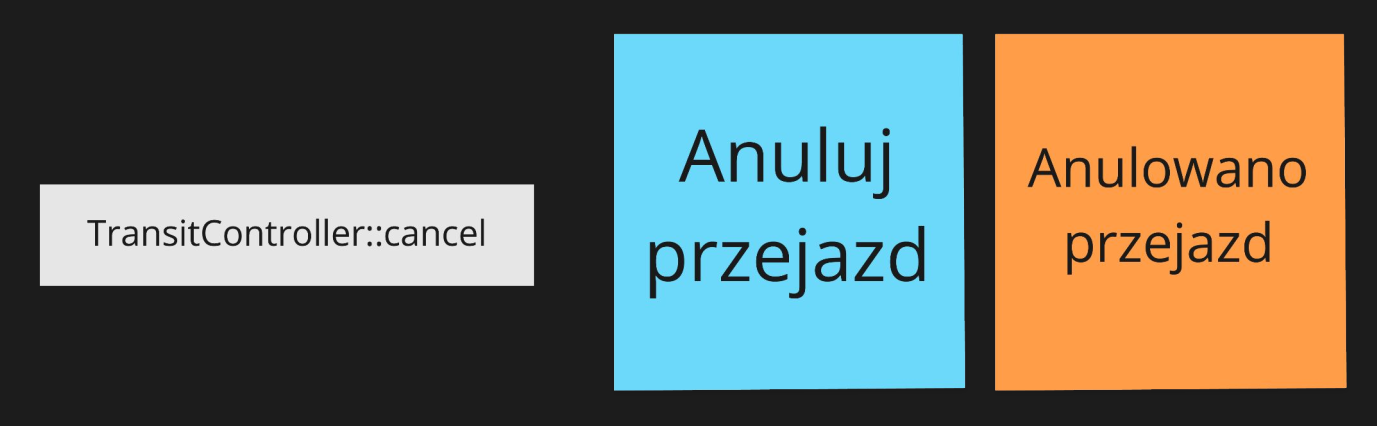
W systemie taksówkowym występuje zdarzenie "Anulowano Przejazd". Analizując kod źródłowy projektu, można powiązać wystąpienie tego zdarzenia z wywołaniem metody cancel kontrolera TransitController. Można byłoby powiedzieć, że operacja "Anuluj Przejazd" skutkuje odnotowaniem "Anulowano Przejazd". Jednak interesariusze biznesowi od razu wskazują tu, że oczekiwanych zachowań jest więcej:
- możliwość podjęcia przez kierowcę kolejnego zlecenia,
- pobranie od zamawiającego opłaty karnej, jeśli tylko kierowca zdążył podjąć kurs i rozpocząć dojazd.
Obecnie jednak oprogramowanie nie wspiera drugiej z tych funkcji, ponieważ była trudna do wprowadzenia. Wszystkie procesy związane z wypłatą zwrotów dla kierowców są realizowane poza systemem, na różnego rodzaju arkuszach i raportach.

Mamy tu sytuację, w której obserwowalne zachowania zależą od stanu przejazdu i w prosty sposób można wskazać dwa scenariusze.
Znając wszystkie trzy części tj. stan wejściowy, wykonywaną operację oraz zestaw obserwowalnych zachowań możemy zbudować na odpowiedniej warstwie systemu siatkę bezpieczeństwa. Dzięki temu obawy przed wprowadzeniem zmiany w systemie powinny zostać wyeliminowane.
Punkty zapalne - Hot-Spots
Projekt legacy zwykle jest dotknięty różnymi problemami. Gdyby nie był — nie byłby legacy, a kolejne zmiany i funkcje wprowadzałoby się bez żadnego wysiłku. W trakcie mapowania stanu As-Is projektu staramy się więc również uchwycić i ten jego aspekt. EventStorming oferuje tu pojęcie punktu zapalnego, tak zwany Hot-Spot, który może posłużyć do wskazania powiązanych problemów lub ryzyk. Im więcej takich miejsc uda się ujawnić zarówno technicznych, jak i biznesowych, tym lepszy będzie punkt wyjścia do myślenia o pozbawionym tych wad rozwiązaniu To-Be.
Hot-Spots:
- istniejący lub potencjalny problem w oprogramowaniu bądź procesie biznesowym
- wątpliwość
- ryzyko projektowe
- pytanie bez odpowiedzi
Oczywiście nie każdy zidentyfikowany Hot-Spot zostanie od razu naprawiony i usunięty. Może być różna częstotliwość występowania czy istotność poszczególnych problemów. Problem zidentyfikowany jako "Raport dobowy kierowców generuje się wolno" będzie zupełnie inną pobudką w sytuacji, gdy w planach biznesowych organizacji jest udostępnienie całego systemu innym operatorom, niż gdy jedynym użytkownikiem tej funkcji biznesowej jest wewnętrzny dział kontroli.
Nie w każdym projekcie czy zespole rozmowa na takie tematy jest łatwa i przyjemna, dlatego ważnym jest również skupienie się na komunikacji w zespole i jej "refaktoryzacji".
Struktura sesji Big Picture
Literatura opisuje następujące etapy Big Picture EventStormingu:
- Wild Exploration
- Enforce The Timeline
- Users & Systems
- Reverse Narrative
- Value Mapping
- Opportunites
- Choose The Right Problem
Jednak do pozyskania przydatnej podczas refaktoryzacji wiedzy nie potrzebujemy wykonywać ich wszystkich. Wejście w dyskusję na temat przepływów wartości w procesach biznesowych nie posunie nas ani krok do przodu, gdy celem jest zmiana struktury rozwiązania przy utrzymaniu jego obserwowalnych zachowań. Dlatego też wykonujemy tylko te kroki i działania, które mają wartość w danej sytuacji i projekcie.
Znajomość stanu As-Is, w którym obecnie znajduje się projekt to jednak dopiero połowa sukcesu. Trudniejsza część to modelowaniem struktury rozwiązania docelowego To-Be, którym chcemy dysponować w przyszłości, z poprawnie wydzielonymi granicami obiektów, modułów czy innych elementów.
Pierwsza sesja EventStormingu w projekcie Cabs
Jest to dobry moment, aby zobaczyć, jak sesja EventStormingu może wyglądać praktyce dla projektu Cabs: "Lekcja 1.9. Sesja Big Picture EventStorming"
Efekt sesji możesz zobaczyć również na tablicy w Miro, lub w wersji PDF
Czego warto unikać w początkowym etapie, aby sesja była wartościowa?
Aby sesja EventStormingu przyniosła realną wartość i była pomocna w projekcie, warto pamiętać o kilku zagrożeniach. O organizacji takiego warsztatu możemy myśleć jak o inwestycji, czyli musi nam przynieść konkretny zwrot. Podobnie z resztą jak w przypadku refaktoryzacji.
Nazewnictwo
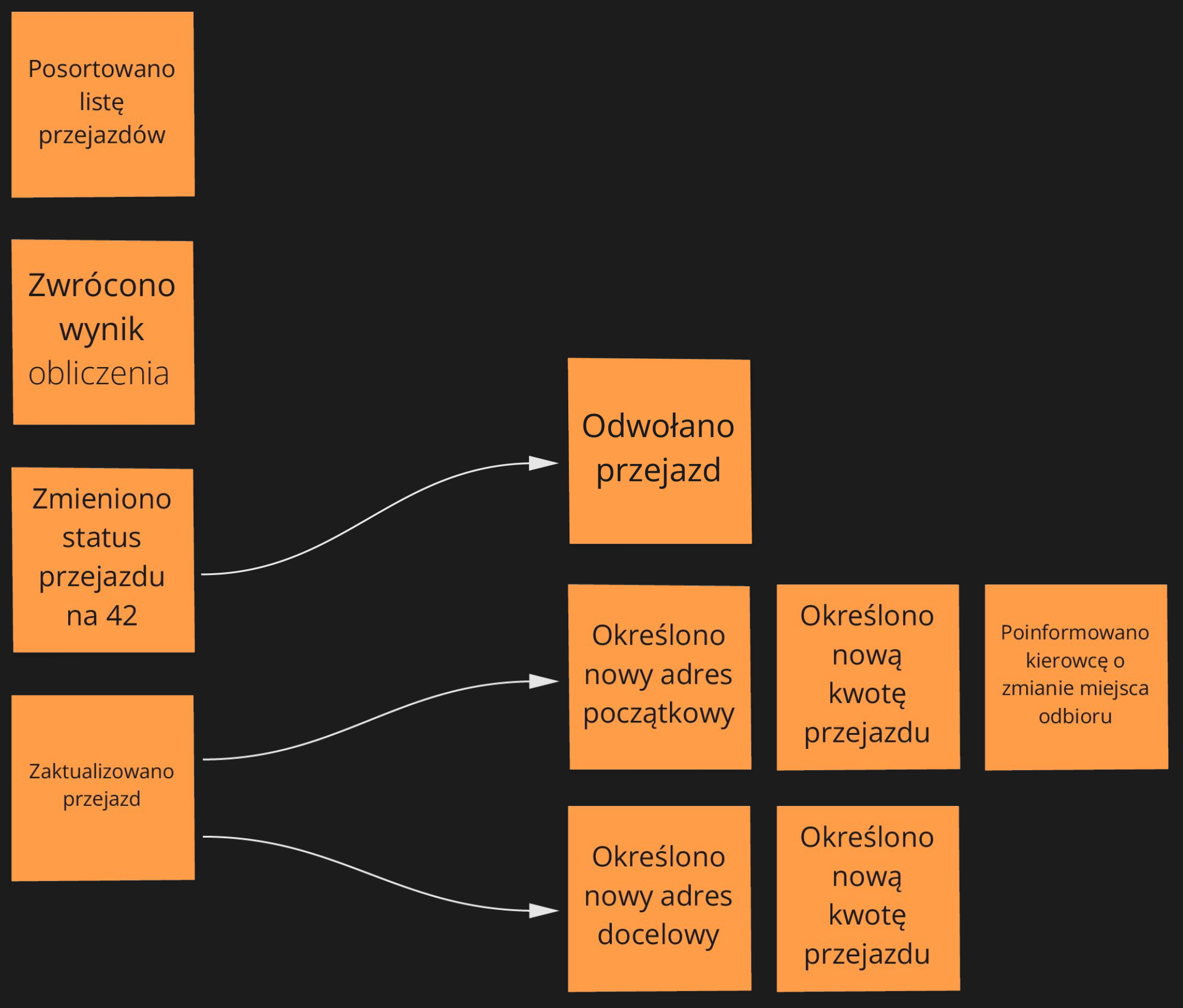
Jeśli sesja zostanie zdominowana przez zdarzenia typu:

To zwrot może okazać się bardzo trudny do uzyskania. Widzimy tu, JAK dany proces działa technicznie krok po kroku, jednak ten aspekt widać znacznie lepiej w edytorze kodu.
Znacznie lepszym podejściem będzie opisanie zmian w procesie językiem biznesowym:
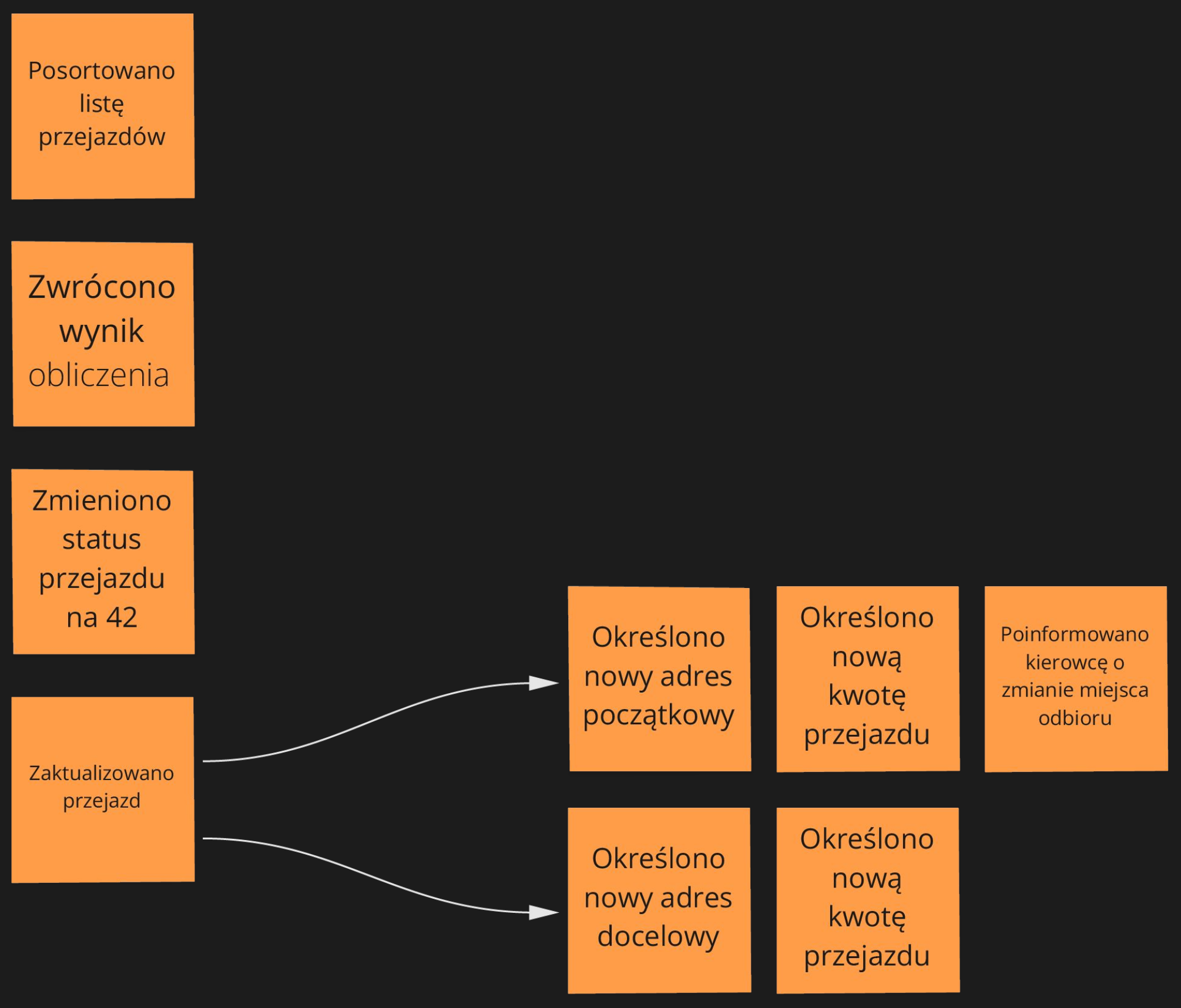
Zamiast "Zaktualizowano przejazd" bardziej precyzyjne byłyby zdarzenia: "Określono nowy adres początkowy" i "Określono nowy adres docelowy". Generują one zupełnie inne konsekwencje. W przypadku adresu początkowego będziemy oczekiwać kolejno zdarzeń "Określono nową kwotę przejazdu" oraz "Poinformowano kierowcę o zmianie lokalizacji", a dla adresu docelowego jedynie obliczenia nowej kwoty przejazdu. Słowa "Zaktualizowano" czy "Zmieniono" mają ogromną tendencję do ukrywania złożoności i wpływu na system. Staraj się ich nie nadużywać.
W przypadku zdarzenia "Zmieniono status przejazdu na 42", lepszym określeniem będzie z kolei zmiana nazwy zdarzenia na "Odwołano przejazd". W innym przypadku osoby nietechniczne prawdopodobnie poczują się zagubione i wyłączone z dyskusji, z powodu pojawienia się takich magicznych liczb. Można spotkać się z projektami, gdzie użytkownicy znają na pamięć wszystkie możliwe kombinacje statusów i swobodnie się nimi posługują. Nie jest to jednak pożądana sytuacja, ponieważ utrudnia wprowadzanie nowych osób do zespołu i zrozumienie projektu. Dodatkowo status to tylko jedna z możliwości implementacyjnych. Przykładowo w trakcie rozwoju projektu, dużo lepszym rozwiązaniem może się okazać maszyna stanów z dynamiczną konfiguracją.
Zatem pamiętaj, aby zdarzenia opisywać we właściwy sposób, korzystając z języka biznesowego.
Formuła
Drugim istotnym aspektem, jest formuła warsztatu i wykonywane podczas niego kroki.
Przed każdą organizowaną przez nas sesją EventStormingu powinniśmy postawić określony cel. Tym celem może być:
- zmapowanie procesów biznesowych w aktualnej formie,
- przekazanie wiedzy o projekcie nowym osobom w zespole,
- identyfikacja punktów zapalnych,
- modelowanie rozwiązania docelowego,
- poszukiwanie usprawnień w procesie biznesowym lub oprogramowaniu,
- wiele innych.
Jeśli naszym celem jest pozyskanie wiedzy biznesowej, CO właściwie dzieje się w projekcie w celu jego refaktoryzacji, prawdopodobnie nie jest to dobry moment na rozmowy o możliwych modyfikacjach procesu biznesowego, by wykorzystywać nowe rynkowe szanse. Taki warsztat zwykle wymaga innego grona uczestników, a poruszenie takich wątków może też sprawić trudności w osiągnięciu głównego celu sesji.
W przypadku sesji Big Picture w projekcie Cabs takim niechcianym na tym etapie wątkiem byłaby na przykład rozmowa o wyposażeniu kierowców w słuchawkowe zestawy bezprzewodowe. Nie przyniesie ona wymiernych efektów, jeśli chcemy zmieniać wewnętrzną strukturę oprogramowania.
EventStorming jest pewną formułą warsztatową, natomiast jesteśmy uprawnieni również do wyboru kroków tego warsztatu, aby wspierały one wyznaczony wcześniej cel. Możemy także zmieniać ich kolejność w razie potrzeby. Jeśli nawet na etapie Big Picture wprowadzenie Rozkazów czy Polityk (ES) uznamy za pomocne, zróbmy to. Nie czekajmy z wprowadzeniem tych elementów do kolejnych warsztatów, ponieważ w literaturze pojawiają się one właśnie na takim etapie. Być może dzięki temu lepiej zrozumiemy stojący za projektem biznes i jego odwzorowanie w kodzie systemu.
Przykładowo w sesji dla projektu Cabs, gdzie prowadzona jest sesja rozpoznania, już na etapie Big Picture wprowadzonych zostało kilka rozkazów:
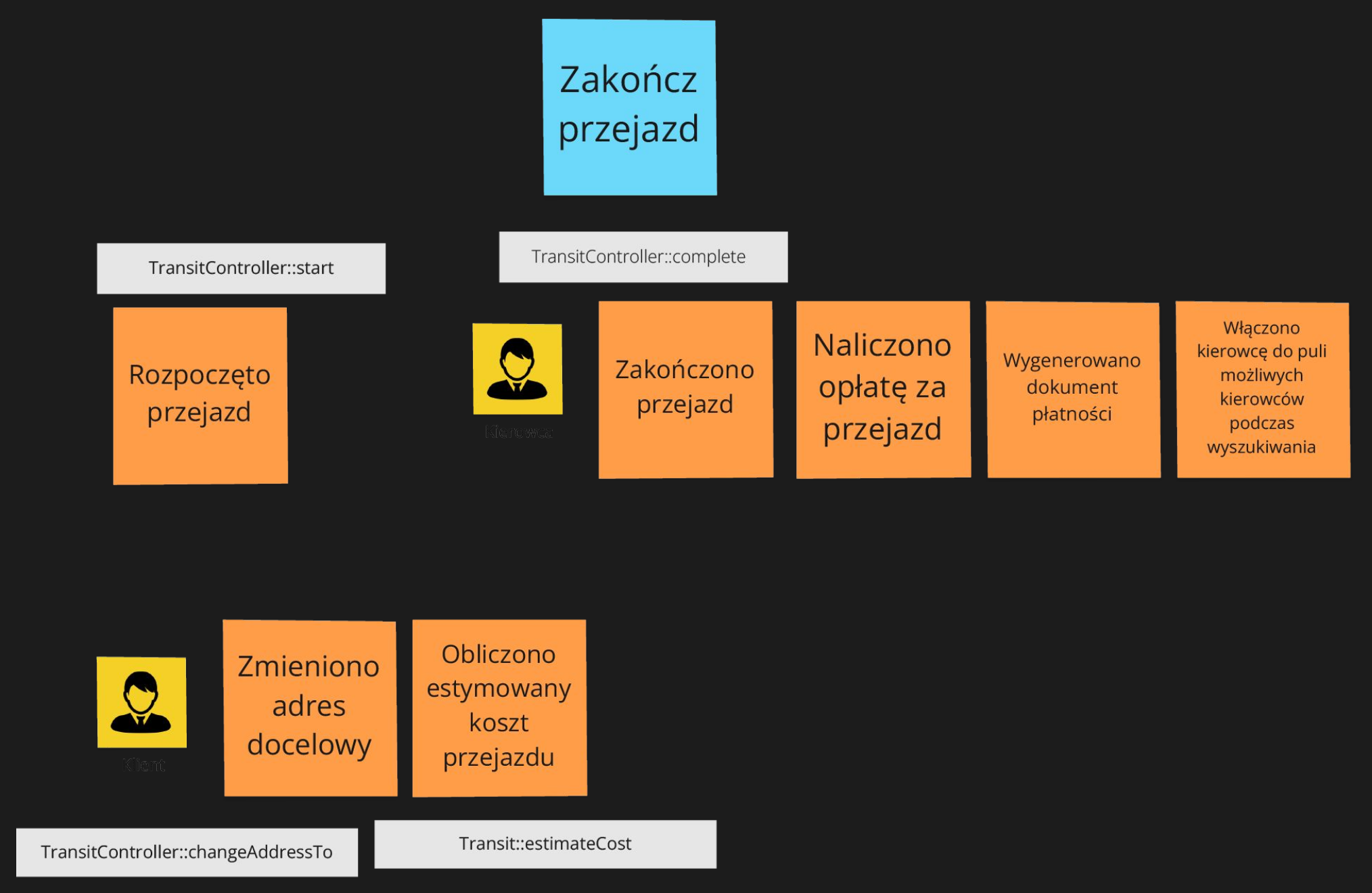
Powiązane dzięki temu zostały obserwowalne zachowania systemu (zdarzenia) z interfejsem aplikacji, co pozwoliło z kolei na utworzenie kilku scenariuszy testowych na przyszłość.
No Silver Bullet
Jako programiści spotykamy się z różnego rodzaju projektami. Czasem są to bardzo bogate w zachowania systemy biznesowe, czasem aplikacje Big-Data, a czasem po prostu systemy typu "przeglądarka do bazy danych". EventStorming nie jest mitycznym Silver Bullet, rozwiązującym każdy problem w każdym projekcie. To tylko narzędzie i tak powinno być traktowane. Jeśli narzędzie Cię ogranicza, spowalnia, czy też nie pasuje do natury rozwiązywanego problemu, zmień je na inne. Odbędzie się to z korzyścią dla ROI i całego projektu.
Zwróć uwagę na następujący kod:
public class TransitAnalyzer {
private List<Address> analyze(Client client, Address from, Transit t) {
List<Transit> ts;
if (t == null) {
ts = transitRepository
.findAllByClientAndFromAndStatusOrderByDateTimeDesc(
client, from, Transit.Status.COMPLETED);
} else {
ts = transitRepository
.findAllByClientAndFromAndPublishedAfterAndStatusOrderByDateTimeDesc(
client, from, t.getPublished(), Transit.Status.COMPLETED);;
}
if (ts.size() > 1000 && client.getId() == 666) {
ts = ts.stream().limit(1000).collect(Collectors.toList());
}
if (t != null ) {
ts = ts.stream()
.filter(_t ->
t.getCompleteAt().plus(15, ChronoUnit.MINUTES).isAfter(_t.getStarted()))
.collect(Collectors.toList());
}
if (ts.isEmpty()) {
return List.of(t.getTo());
}
Comparator<List> comparator = Comparator.comparingInt(List::size);
return ts.stream()
.map(_t -> {
List<Address> result = new ArrayList<>();
result.add(_t.getFrom());
result.addAll(analyze(client, _t.getTo(), _t));
return result;
})
.sorted(comparator.reversed())
.collect(Collectors.toList())
.stream().findFirst().orElse(new ArrayList<>());
}
}
Przedstawia on algorytm wyliczenia pewnej wartości w dość skomplikowany sposób. Każdy krok tego algorytmu można opisać zdarzeniem. Jednak efektywniejsze będzie przedstawienie tego algorytmu w postaci schematu blokowego, ponieważ został on zaprojektowany dokładnie do takich zadań. Warto pamiętać o tym przy kolejnych sesjach.
A jeśli skupimy się na innych zdarzeniach?
Warsztat w systemie Cabs mógłby być dużo mniej efektywny, gdyby pominąć kilka istotnych aspektów facylitacji tej sesji. Warto rozważyć kilka przykładów.
Kontrakty
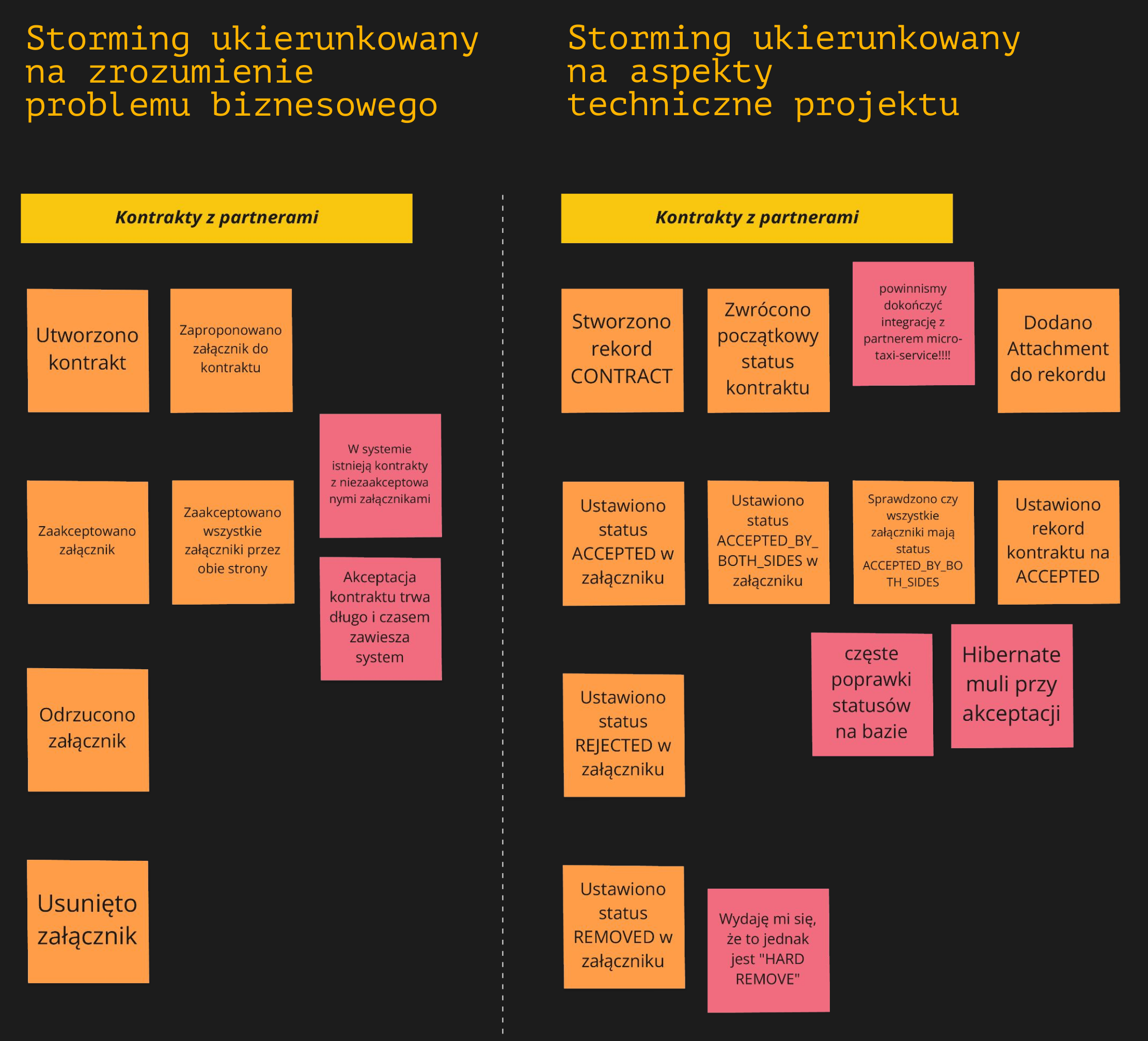
Przy kontraktach partnerskich prawdopodobnie nie interesują nas statusy w bazie danych. Jest to tylko specyficzny sposób reprezentacji niektórych akcji biznesowych, których dokonujemy z naszymi partnerami. Możesz myśleć, że nie jest to problem, ponieważ nawet mówiąc statusami, jesteś w stanie zrozumieć, co tu się dzieje. I faktycznie czasami to nie będzie powodować problemu, ale taki sposób rozmowy może wykluczać z niej osoby, które nigdy tych statusów nie widziały w bazie. Przecież one nie muszą wypływać do interfejsu użytkownika. Najpewniej są to osoby z wiedzą biznesową, a skoro one zostały wykluczone z rozmowy, bo nie rozumieją tego języka, to konsekwencje mogą być jeszcze poważniejsze — po prostu w procesie umknie nam coś istotnego. Ponadto, rozmawianie o problemie jego specyficzną bazodanową strukturą, oddala od innego, potencjalnie, łatwiejszego rozwiązania.
Zdarzenia środowiskowe i interfejsowe
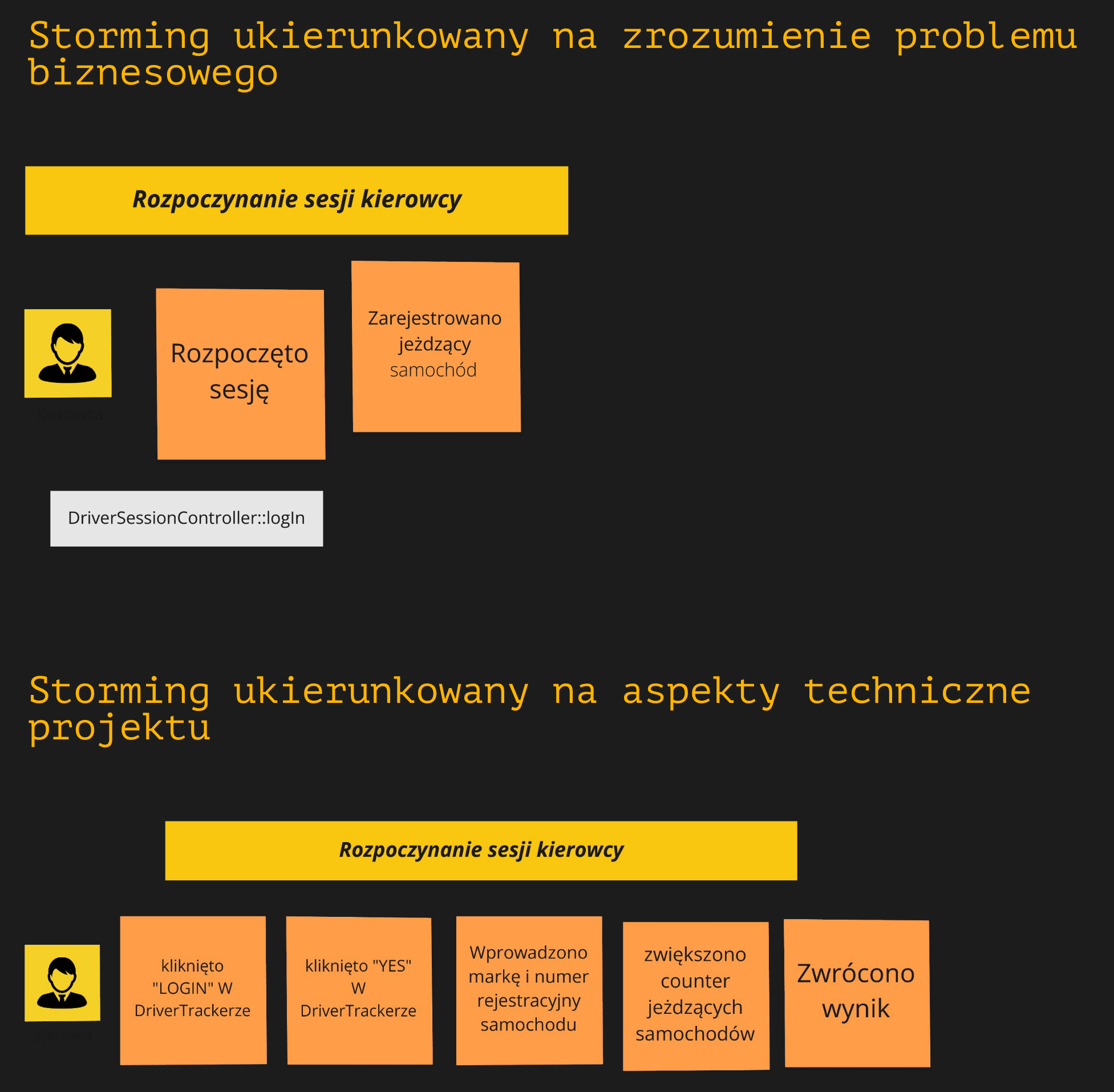
Przy rozpoczęciu sesji przez kierowcę nie będzie nas interesować, że włączył silnik lub że nacisnął specyficzną kombinację przycisków w aplikacji mobilnej. Natomiast ważną zmianą stanu w naszym procesie jest to, że kierowca zalogował się do systemu i jest dostępny dla pasażerów. Nie ma to większego znaczenia, czy zrobił to przykładowo telefonicznie, prosząc administratora o taką zmianę, bo akurat rozładowała mu się bateria w telefonie.
Gdyby celem naszej sesji była poprawa tzw. user experience aplikacji mobilnej, to reguły gry by się zmieniły. To, co trzeba w tej aplikacji zrobić, nagle stanowiłoby esencję naszego problemu. Pamiętajmy, że na ten moment chcemy po prostu poznać główne procesy w systemie, który będziemy refaktorować. Znowu możesz zacząć się zastanawiać jaki problem ten dokładniejszy opis powoduje. Zauważ, że zabiera nam energię, czas i zaszumia sedno naszej sesji. Mamy ograniczone możliwości kognitywne, a wykorzystujemy je niezgodnie z celem. W większej skali, przy większej liczbie zdarzeń, będzie to stanowić poważny kłopot. Pamiętajmy, że na warsztacie nie jesteśmy też sami.
Zdarzenia infrastrukturalne
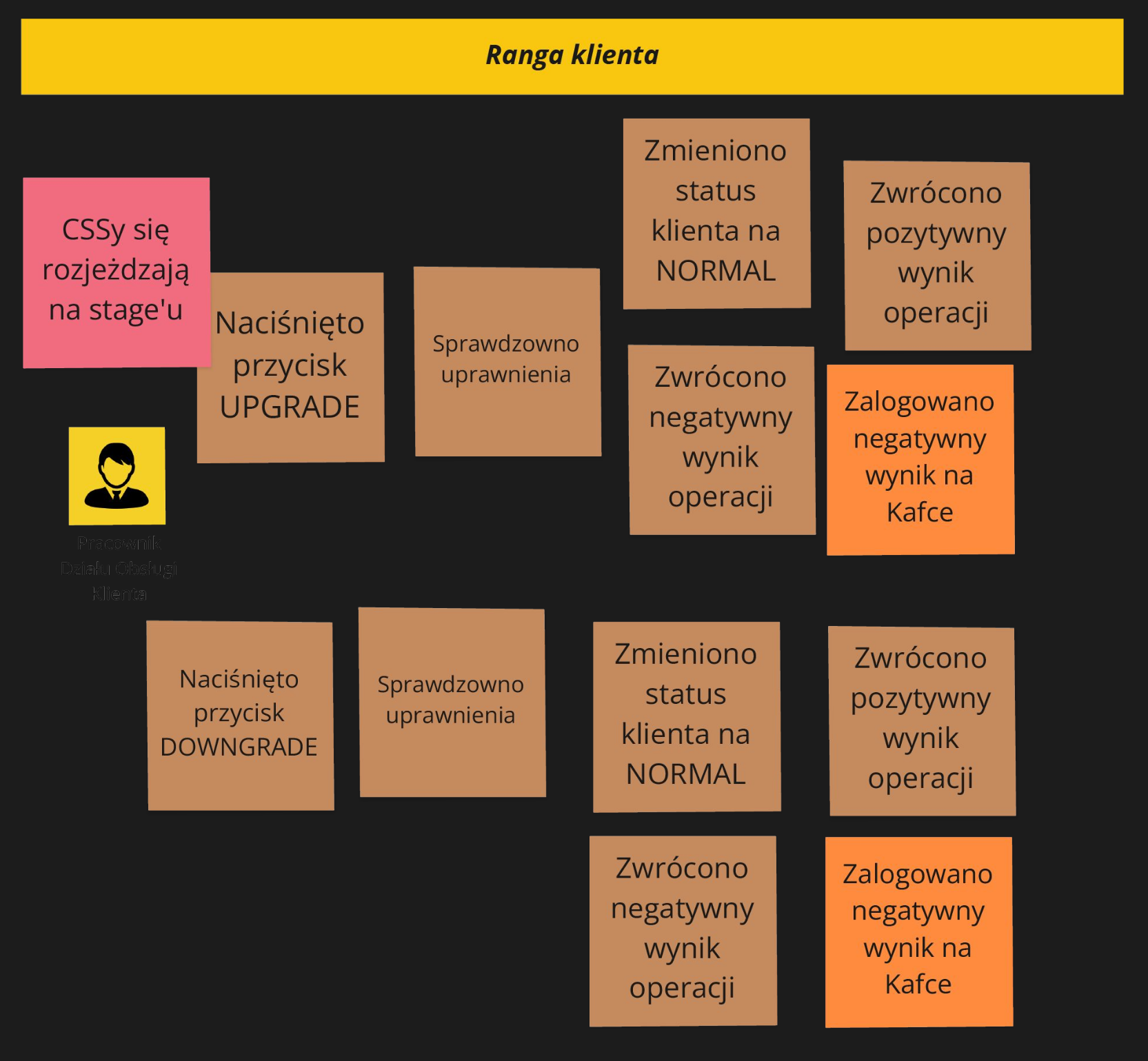
Podobnie będzie ze zdarzeniami, które sugerują zalogowanie wyniku na Kafce i zwrócenie wyniku obliczeń. To specyficzny detal techniczny, który tak samo, jak w poprzednim przykładzie: utrudnia zrozumienie całego procesu, dodaje szumu i zabiera nam czas.
Algorytmika
Ostatni przykład to proces wyszukiwania kierowców, który został rozpisany krok po kroku:
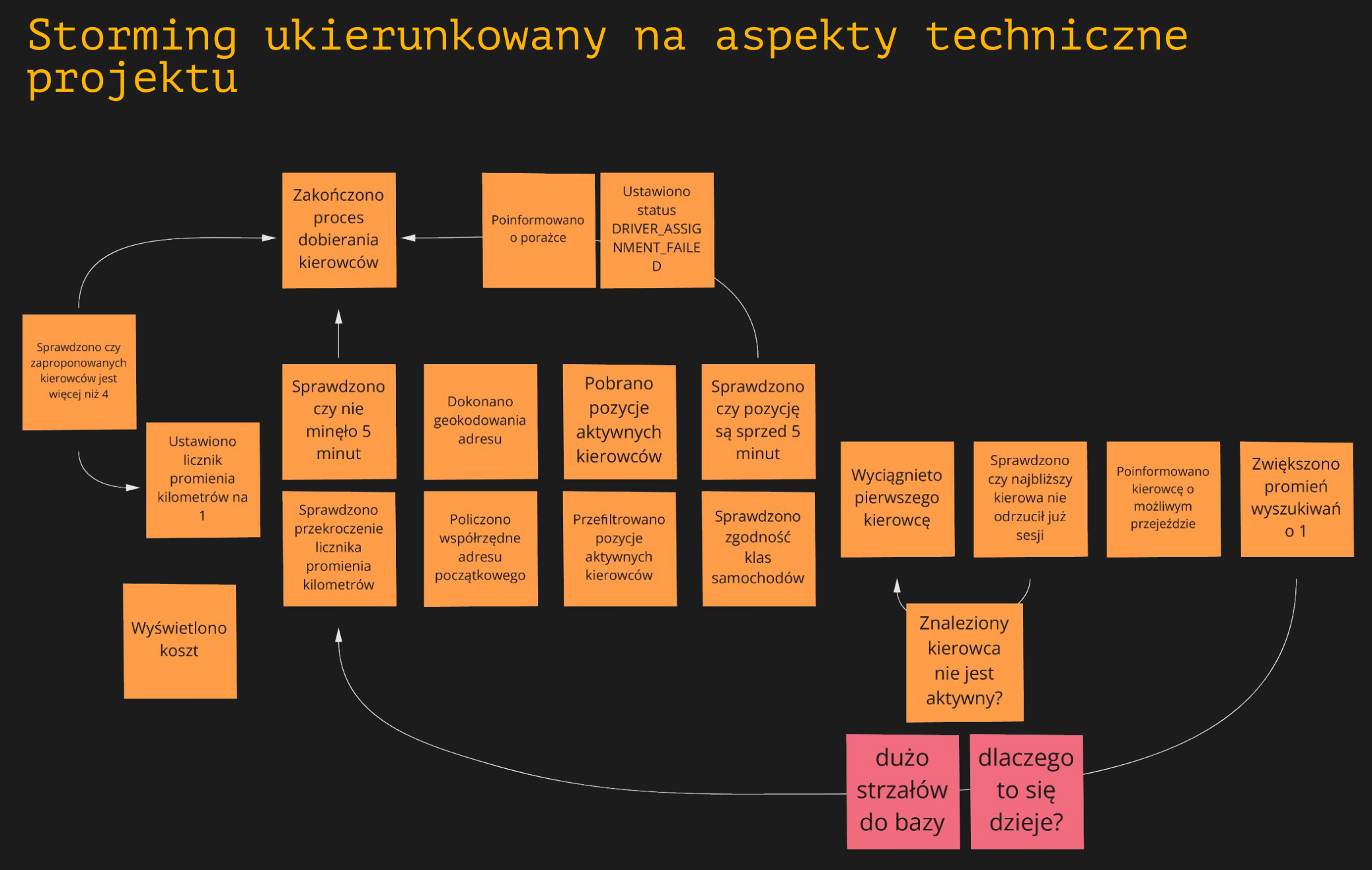
Zdominował on sesję i zajął pierwsze 30 minut. Programiści kilkukrotnie sprawdzali jego poprawność w IDE, upewniając się co do każdego kroku. Może to być wskazówka, że właśnie IDE nie jest tutaj lepszym miejscem do tego typu analiz. Skutkiem działania tego algorytmu jest dopasowanie kierowcy. To, w jaki sposób się to robi i dokładne szczegóły nie powinny nas w tym momencie interesować. Być może niektóre detale są ważne, ale wejdziemy w nie głębiej, kiedy będzie taka potrzeba. I tak nie zapamiętamy wszystkich tych kartek, i tak będziemy musieli do nich wracać. Zapamiętamy za to kartkę ze skutkiem — "DOPASOWANO kierowcę". Skupmy się więc na obserwowalnych zachowaniach, a nie na szczegółach implementacyjnych. Samo mapowanie obserwowalnego zachowania do kodu w zupełności wystarczy.
Cel
Jeśli nie skupimy się na celu sesji i nie ustawimy jej kontraktu, to jest duża szansa, że nie osiągniemy niczego. Możemy skończyć z koncertem życzeń nowych wymagań biznesowych, które dobrze byłoby mieć na wczoraj. Dowiemy się sporo o wolnych testach czy konfliktach w zespole. Jest to pożyteczna wiedza, ale nie pomaga skupić się na zrozumieniu procesu, zmapowaniu go do kodu i wyłapaniu bolączek, które muszą być poddane refaktoryzacji.
Porównanie
Na koniec możesz też porównać sobie rezultaty obu sposobów poprowadzenia warsztatu:
Podsumowanie
Warto zapamiętać
często ciężko jest zrozumieć system klasy legacy
Event Storming to technika warsztatowa, która może w tym pomóc
w legacy często wykonuje się warsztat As-Is i warsztat To-Be
Event Storming nie ma sztywnych ram, warsztat i jego elementy dopasowujemy do potrzeb konkretnego środowiska
za pomocą zdarzeń domenowych możemy odkryć "CO" robi system i zmapować jego obserwowalne zachowania do kodu
pomaga to odkryć kluczowe scenariusze testowe i zbudować siatkę bezpieczeństwa
Materiały: