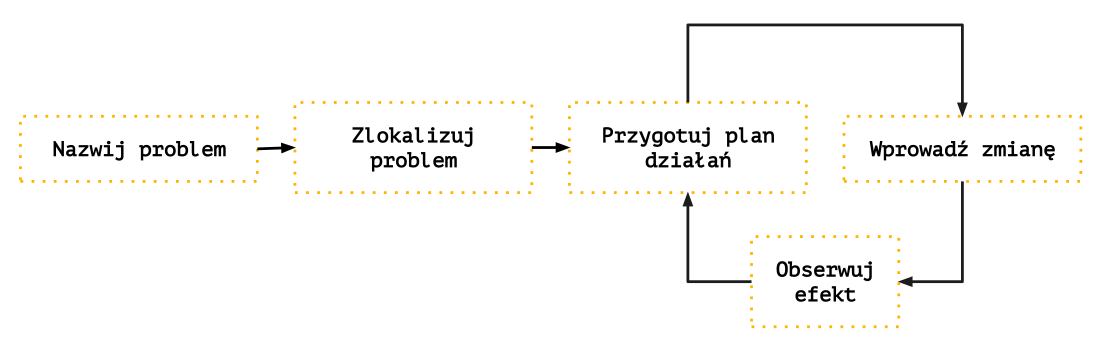
Generalna Ścieżka Refaktoryzacji
Na metapoziomie, niezależnie od zakresu refaktoryzacji, można wyróżnić kilka takich samych kroków, które podejmujemy, żeby taką refaktoryzację pozytywnie skończyć. Kroki te tworzą ścieżkę, którą nazywamy Generalną Ścieżką Refaktoryzacji. Ścieżka ta rozwijana jest o kolejne kroki, w zależności od postępu szkolenia.
Punktem startu jest zawsze nazwanie problemu. W wielu przypadkach wydaje się to oczywiste, ale mimo wszystko warto w głowie rozplątać nazywanie konkretnej bolączki w kodzie i dobieranie do niej rozwiązania. Powinniśmy tak robić, ponieważ często mogą nas oszukać skróty myślowe, które wypracowaliśmy poprzez pracę z innymi projektami. Spójrz na ten kod:
private CarType.Status status;
private Instant lastChange;
private int carsCounter;
private String description;
private int activeCarsCounter;
public Long getId() {
return id;
}
public CarType.CarClass getCarClass() {
return carClass;
}
public void setCarClass(CarType.CarClass carClass) {
this.carClass = carClass;
}
public CarType.Status getStatus() {
return status;
}
public void setStatus(CarType.Status status) {
this.status = status;
}
//...
Pierwszą reakcją może być chęć usunięcia getterów i setterów, czyli wprowadzenie enkapsulacji. Możesz być motywowany tym, że jej brak jest antywzorcem, lub w poprzednim projekcie mieliście dokładnie z tym problem. Jeśli nie zadasz sobie pytania: "Jaki problem to w tym projekcie, w tym miejscu systemu, powoduje?", to być może zwrot z inwestycji będzie zerowy.
Nasz system w różnych miejscach powinien zapewniać różne tzw. "drivery architektoniczne", czyli czynniki determinujące styl architektury czy kodu. W niektórych miejscach oczekujemy wydajności, w innych — czytelności. Dochodzi też wektor czasu — być może miejsca, które nie musiałyby być testowalne, nagle takimi muszą się stać. Nazywanie problemów to najczęściej nic innego jak punktowanie braku realizacji tych driverów przez nasz system.

Wracając do wcześniejszego kodu, gdy zastanowimy się, do czego jest używany, możemy natrafić na ewentualny problem. Może nim być jakaś specyficzna reguła pomiędzy datą a statusem. Na przykład zmiana statusu zawsze musi skutkować ustawieniem daty tej zmiany, bo w przeciwnym przypadku mamy niespójne dane. To jest właśnie konkretny problem, ponieważ system łatwo wpada w stan niespójności, przez to, że dane są ze sobą silnie związane, a nasz kod tego związania nie zabezpiecza.
Kolejnym konkretnym problemem, może być częsta zmiana statusu, przez co kombinacja tych dwóch albo większej liczby setterów powoduje duplikację kodu i obniżenie jego stabilności:
setLastChange(Instant.now());
setStatus(CarType.Status.INACTIVE);
setDescription("Klasa samochodów ECO, wyłączona z użytku");
//..
setLastChange(Instant.now());
setStatus(CarType.Status.INACTIVE);
setDescription("Klasa samochodów ECO, wyłączona z użytku");
//..
setLastChange(Instant.now());
setStatus(CarType.Status.INACTIVE);
setDescription("Klasa samochodów ECO, wyłączona z użytku");
Do omawianego kodu, można podejść z jeszcze jednej strony: otóż może to być część tzw. DTO — klasa, która transportuje dane i nie jest obiektem w rozumieniu programowania obiektowego.
public class CarTypeDTO {
private Long id;
private CarType.CarClass carClass;
private CarType.Status status;
private Instant lastChange;
private int carsCounter;
private String description;
//..
}
W takim przypadku klasa ta nie potrzebuje enkapsulacji, a problemem może być liczba setterów i getterów oraz konieczność ich ciągłego dodawania — tak zwany boilerplate. Istnieje kilka różnych sposobów rozwiązania tego problemu, w zależności od technologii. Możemy po prostu ustawić pola jako publiczne, pozbywając się tym samym getterów i setterów:
public class CarTypeDTO {
public Long id;
public CarType.CarClass carClass;
public CarType.Status status;
public Instant lastChange;
public int carsCounter;
public String description;
//..
}
Podsumowując, jeśli przykładowo słyszysz, że:
- jakaś metoda powinna mieć maksymalnie siedem linijek kodu,
- powinniśmy zastosować Value Object,
- w jakimś miejscu brakuje obiektowości,
to zastanów jaki problem to rozwiąże. Czasem jest to oczywisty problem duplikacji albo braku czytelności, ale chodzi o wyrobienie sobie nawyku. Refaktoryzacja powinna przynieść zaplanowane efekty.
Po nazwaniu problemu można wybrać rozwiązanie, a jeśli jest ich kilka to takie, które najbardziej pasuje do kontekstu. W ramach szkolenia przedstawiamy różne problemy, których pewnie miałaś lub miałeś okazję doświadczyć w swojej karierze: - nieczytelny kod, - model niedopasowany do potrzeb biznesu, - naiwna reprezentacja tego biznesu, - duplikacja kodu, - niespójność danych, - niewydajne widoki, - wiele innych.
Niektóre zmiany są proste, a niektóre trochę bardziej złożone, dlatego warto zaplanować sobie pracę. Zastanowić się gdzie zaczynamy, jak zaczynamy albo jak zabezpieczamy się przed błędami. Plany złożonych refaktoryzacji będą bardzo bogate i będą ewoluować w trakcie.
Po każdej zmianie należy obserwować efekty. Na przykład czy duplikacja zniknęła lub ile miejsc w kodzie trzeba zmienić, dodając nowy setter. Innymi słowy, czy widzisz zwrot z poniesionej inwestycji. To pozwala walidować pomysły i ewentualnie korygować plan na kolejne działania.
Kroki Generalnej Ścieżki Refaktoryzacji:
Podsumowanie
Materiały: